【编者按】
生成式人工智能的出现,将人类带入一个机器生成内容与人类原创内容深度交织的世界。
以 Sora、Midjourney为代表的AIGC模型,展示了人类通向通用人工智能(AGI)的想象力,也让虚假影像以前所未有的速度涌入公共空间,而人类的识别速度却远远落后于造假的节奏。
在此背景下,“以AI辨AI”似乎成为一种可行的思路。我们好奇,人工智能能否辅助核查员和读者完成核查工作?大模型如何定义“真实“的边界?
为了解答这些疑问,“澎湃明查“发起挑战,将ChatGPT、Gemini、DeepSeek、豆包等热门模型请上了实验台。
背景
两年前,澎湃明查曾做过一项实验,测试几款生成式人工智能工具在核查文字虚假信息方面的能力。
当时,我们选取了微软的BingChat、百度的“文心一言”,以及智能问答搜索工具Perplexity AI。测试内容是已经被权威机构确认的虚假信息。结果显示,这些AI工具虽然能提供一些参考信息和推理线索,但在判断真假时仍容易出现“幻觉”或错误。
两年过去,技术发展迅速——GPT-5的出现让AI不仅能处理文字,还能理解图片、视频和音频等多模态信息;豆包(Doubao)、Claude等新的模型后来者居上,在判断事实一致性和推理透明度上优势显著……
这是否意味着,大模型在核查信息方面的能力也可能已有显著提升?为此,我们开展了新一轮测试。
这一次,我们挑选了四款市面上主流、风格各异的AI模型:Anthropic推出的Claude Sonnet 4、OpenAI的ChatGPT-5、字节跳动旗下的豆包和中国初创团队开发的DeepSeek。
测试规则沿用了两年前的标准:每款模型都要判断20条已经被核查机构确认的虚假信息,其中10条为中文,10条为英文,发布时间均在2025年,内容涉及健康、科技、时政和社会等多个领域。
我们对AI的反馈进行打分。标准仍然是:回答正确得1分,回答错误得0分,在不确定消息真假情况下提示用户注意甄别得0.5分,满分为20分。
明查
与两年前的测试结果显著不同,如今的大模型在检验已被证伪的虚假信息方面的表现可谓亮眼——四款模型的平均分达到了19.125分,其中两款甚至获得了满分。这说明,至少在核查已被验证的虚假信息时,现有的大模型已经基本能够做到准确无误。
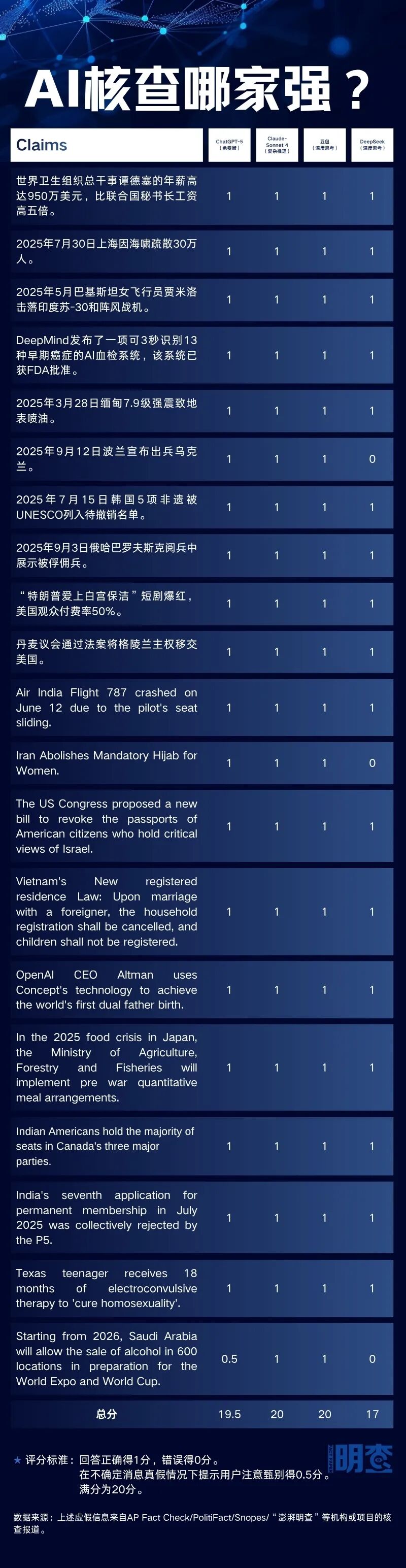
获得满分的模型分别是Anthropic的Claude和字节跳动旗下的豆包。两款模型对输入信息的真实性均做出了正确判断,并展示了完整的分析思路。
我们观察到,Claude在分析问题时,会将虚假说法中的内容进行拆解,逐一分析,并尝试从不同角度切入,交叉验证信息。例如,在验证“OpenAI CEO 奥尔特曼是否利用 Concept的技术实现了世界上首例双父生子”的内容时,Claude的分析角度含括了网传的奥尔特曼生子所使用的技术、Concept公司拥有的技术、双父生子技术发展的现状和奥尔特曼本人的声明等。
豆包同样会在核查过程中将信息中的关键要素进行拆解,但更倚仗权威媒体或权威机构的信息。例如,在对“短剧《特朗普爱上白宫保洁》风靡海外”这一信息进行查证的过程中,豆包AI首先确认了短剧名称和平台,查证该剧是否存在,然后核查了是否有媒体报道1.5亿营收和50%付费率,同时查证好莱坞演员收入激增的说法是否属实,最终综合判断该信息为虚假信息。

大模型会在核查过程中将信息中的关键要素进行拆解。
在验证“女性飞行员贾米洛驾驶歼-10战斗机击落印度阵风战机”的信息时,豆包反复强调在印巴两国发布的官方通报中没有显示此类信息。此外,豆包习惯于在解释完一则信息的证伪逻辑后,附上与虚假信息的传播逻辑与动机相关的内容,这也是其区别于另外3个模型的特点。

豆包习惯于在解释完一则信息的证伪逻辑后,附上与虚假信息的传播逻辑与动机相关的内容。
就最终的得分而言,国产大模型DeepSeek在回答的精准性上稍显逊色。在使用中英文分别向DeepSeek进行提问的过程中,DeepSeek均有错误的回答生成。
尽管如此,该模型在每一条回答后,都会显示“本回答由AI生成,内容仅供参考,请仔细甄别”的内容。除了给出核查结论以及核查过程,DeepSeek还会给出“如何识别此类信息”的提醒。
在信源的使用上,DeepSeek倾向于采用来自事实核查机构的报道。在多条核查信息中,DeepSeek都抓取了“澎湃明查”的事实核查新闻。

DeepSeek会给出“如何识别此类信息”的提醒。
在核查风格方面,四款模型中,ChatGPT给出的结论往往更加中立、也更加简明。由于众多传播于网络空间中的虚假信息往往是捕风捉影,可能基于一定事实。在面对这样的信息时,ChatGPT即便认定一则说法整体上是失实的,也还是会将其中与事实相符的部分呈现出来。

ChatGPT在认定一则说法整体上是失实同时,会将其中与事实相符的部分呈现出来。
Claude在呈现核查结果时,语气更为强烈,常常使用“这是假新闻”“这是虚假信息”“这是完全虚假的信息”等表述。相较于ChatGPT的回答,这样的表达更为绝对,有时会遗漏部分与提问相关的信息。
综合来看,上述测试结果显示,现有的大模型较两年前已经有了长足的进步,可谓具备了基本的核查功能。不同模型的核查风格存在差异,用户可以根据需求选择使用。
除文字外,我们观察到,有的大模型也已经具备多模态搜索的能力。接下来,“澎湃明查”将围绕AI生成的图片和视频进行更多的测试。欢迎大家在评论区分享意见或建议。

海报设计 白浪



